Image recognition
Description
I am going to create a deep learning model of image recognition by means of a convolution neural network.
The dataset that I will use to train this model consists of 10000 photos of dogs and 10000 photos of cats. These photos as you can see in the following images are totally different between them so that the model manages to capture the most general features between the dog and the cat.
Convolutional neural network steps
Just like any other Neural Network, I use an activation function to make our output non-linear. In the case of a Convolutional Neural Network, the output of the convolution will be passed through the activation function. This could be the ReLU activation function.
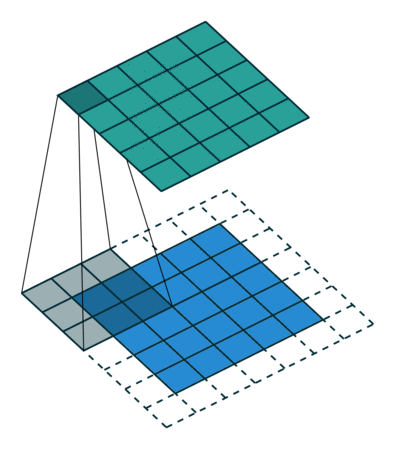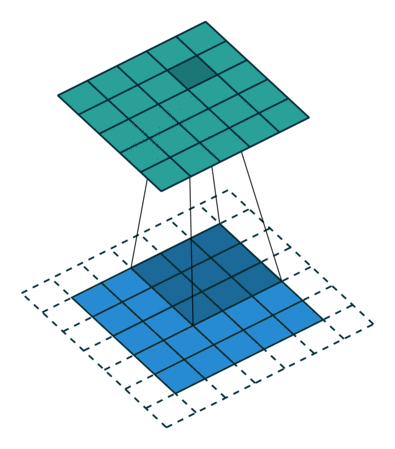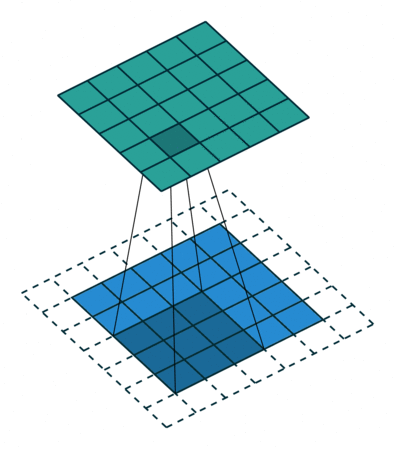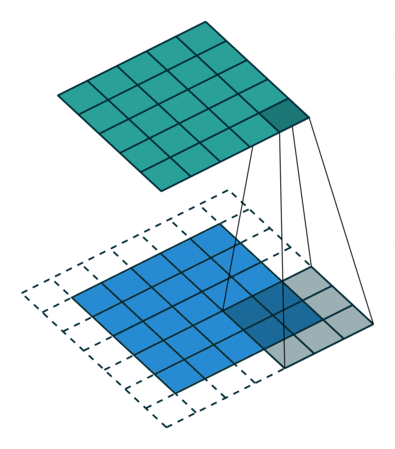
Stride is the size of the step the convolution filter moves each time. A stride size is usually 1, meaning the filter slides pixel by pixel. By increasing the stride size, your filter is sliding over the input with a larger interval and thus has less overlap between the cells.
The animation below shows stride size 1 in action.
Because the size of the feature map is always smaller than the input, I have to do something to prevent our feature map from shrinking. This is where it is used padding.
A layer of zero-value pixels is added to surround the input with zeros, so that our feature map will not shrink. In addition to keeping the spatial size constant after performing convolution, padding also improves performance and makes sure the kernel and stride size will fit in the input.
After a convolution layer, it is common to add a pooling layer in between CNN layers. The function of pooling is to continuously reduce the dimensionality to reduce the number of parameters and computation in the network. This shortens the training time and controls overfitting.
The most frequent type of pooling is max pooling, which takes the maximum value in each window. These window sizes need to be specified beforehand. This decreases the feature map size while at the same time keeping the significant information.
For the convolution layer and max pooling, 4 layers I have been used.
In the first two layers has been used 32 features detectors tamanho 3x3, padding "same", the photos are going to stay with the initial size of 150x150 and an activation function relu.
In the last two layers, I have used the same hyper parameters but adding more features detectors to a total of 64.
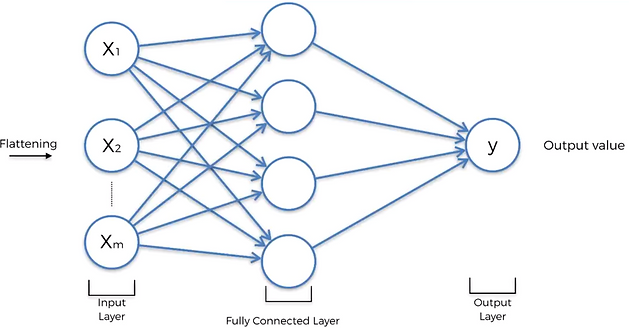
Flattening layer
After the convolution and pooling layers, our classification part consists of a few fully connected layers. However, these fully connected layers can only accept 1 Dimensional data. To convert our 3D data to 1D, I use the function flatten in Python. This essentially arranges our 3D volume into a 1D vector.
Fully connected layers
The last layers of a Convolutional NN are fully connected layers. Neurons in a fully connected layer have full connections to all the activations in the previous layer. This part is in principle the same as a regular Neural Network.
I have used 3 hidden layers with 64 units and with relu activation.
The last layer have a unit and a sigmoid activation function, since it is a case of a binary classification, if it were a multiclass classification it would have to be a sofmax activation function.
Compiling the CNN
I have used adam optimizer, as function function binary_crossentropy and as an accuracy metric accuracy.
To be able to enter the images in the neural network they will have to be preprocessed before. For this Keras has some modules inside the module preprocessing.image.
I have to scale the images so that instead of going 0-255 go 0-1. You have to enter the batch size that in this case I have chosen 32 and the size of the images, which should be the same as I have in the neural network.
Finally as the last hyperparameter I put 25 epochs in the algorithm.
Building the CNN
I'm going to use the Keras library to build the convolutional neural network. The number of layers and hyperparameters used in the neural network have been staggered after several training sessions in which the final precision of the model was 92% in the test images.
8000 photos of dogs and 8000 photos of cats have been taken to train and 2000 photos of dogs and 2000 photos of cats to perform the test.
A convolutional neural network consists of 4 steps: Convolution, Max Pooling, Flattening and Full conection.

Convolutional layer and Pooling layer
The term convolution refers to the mathematical combination of two functions to produce a third function. It merges two sets of information.
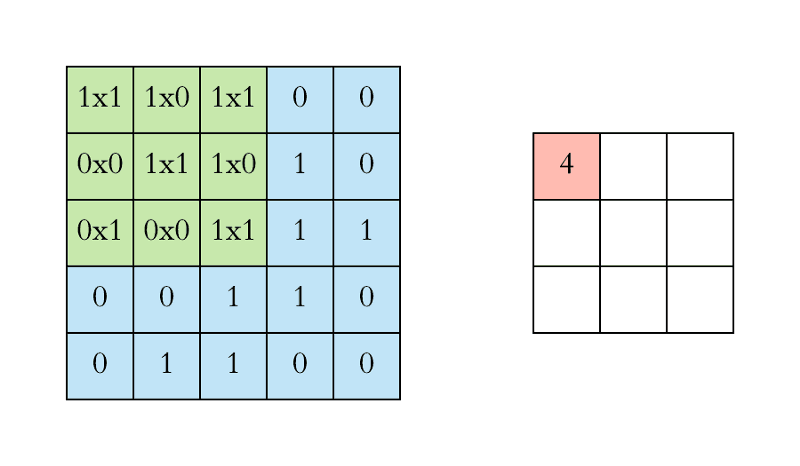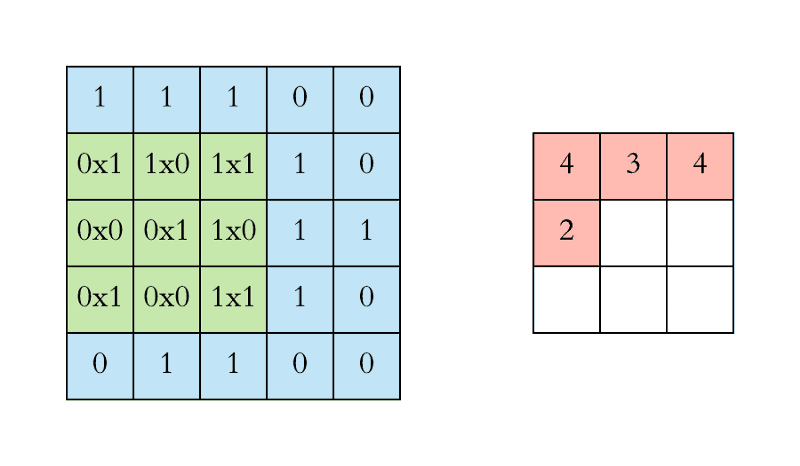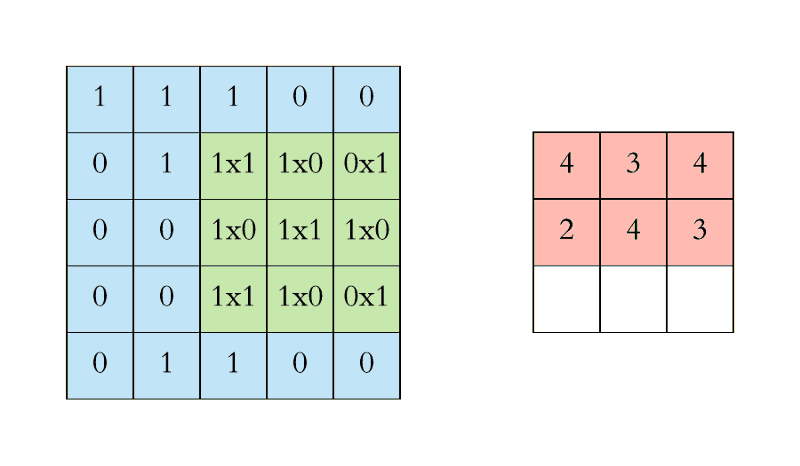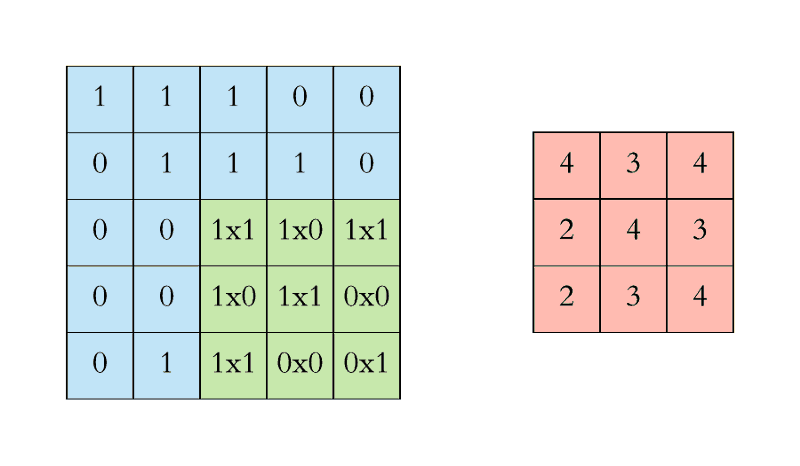
In the case of a CNN, the convolution is performed on the input data with the use of a filter or kernel (these terms are used interchangeably) to then produce a feature map.
A convolution can be executed by sliding the filter over the input. At every location, a matrix multiplication is performed and sums the result onto the feature map.
In the animation below, you can see the convolution operation. You can see the filter(the green square) is sliding over our input (the blue square) and the sum of the convolution goes into the feature map (the red square).
The area of our filter is also called the receptive field, named after the neuron cells! The size of this filter is 3x3.