U.S.A Car Contamination machine learning forecasting
Description
The dataset consists of information regarding vehicles sold in the USA since 1985. This information includes technical details (displacement, type of transmission) and environmental details (gasoline consumption, CO2 emissions).
The original file is at here
The file I am going to use is a modified version (with fewer columns) because of the capacity of my computer to process such amount of data
Description of the Original dataset is here
Objective
The objective of this section is to create a machine learning model capable of forecasting the co2 emissions of cars in U.S.A through the independent variables of the dataset analyzed in the data analysis section.
Preprocessing
In this section I will make an evaluation of nonexistent values, separate the dependent variable and the independent variables and separate the categorical variables from the numerical variables to later create a pipeline to automate the process.
Non existent values
Using the functions of the pandas library I can find the nonexistent values in the dataset.

This is a file that was previously processed in the data analysis phase, so it only shows that there is 2% of nonexistent values in a column, so I decide to eliminate this data.
I could have opted for another solution such as selecting the most common type of traction, but for lack of knowledge in the aera and being such a small amount I decided to eliminate them.
Independent and dependent variables
The objective variable or dependent variable is the variable that will be predicted by the machine learning model. I separate the objective variable and the independent variables I separate them into numerical and categorical variables.
The categorical variables will be transformed into numerical variables by the onehot enconder process.
One hot encoding is a process by which categorical variables are converted into a form that could be provided to ML algorithms to do a better job in prediction.
For reasons of low capacity of the computer software, all the cat- egtical variables minus the traction variable will be eliminated, since when using one hot encoder, columns will be added per variable, which causes many variables to be nested, requiring a higher RAM memory. capacity.
Pipelines
I am going to create a pipeline for the numerical variables, a pipeline for the categorical variables and a pipeline that joins the previous two and uses the regression model chosen.
The numerical pipleine will use an extractor column to separate the numerical variables from the rest and will use a standard escaler to standardize the variables, transforming the variables with mean 0 and standard deviation 1.
The categorical pipeline will use an extractor column to extract the selected category variable and convert it to one hot variables.
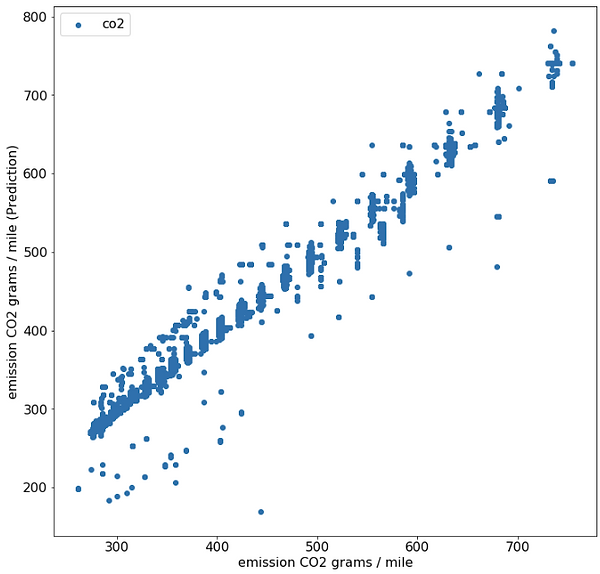
Machine Learning
The type of regression model of this project is a regression model, since the variable to be predicted is the CO2 emitted by the cars.
After several tests the best regressor that has worked in this case has been the regressor xgboost. XGBoost is an algorithm that has recently been dominating applied machine learning and Kaggle competitions for structured or tabular data. XGBoost is an implementation of gradient boosted decision trees designed for speed and performance. Los hiper parametros utilizados para este regresor han sido:
-
max_depth=3
-
learning_rate=0.1
-
n_estimators=100
-
booster='gbtree
The evaluation measures for this model, scores, have been:
-
MAE: Mean Absolute Error
-
RMSE: Root Mean Squared Error
-
R2: R squared
Results